
こんにちは! 機械学習エンジニアの深澤です。
先月、長崎にて開催された言語処理学会第31回年次大会 (NLP2025)に樋口と共に参加してきました。 今年もまたまた過去最多の参加者数となり、言語処理研究の注目度の高まりを感じています。今年は2248人の参加者と777件の発表数を記録しておりました。
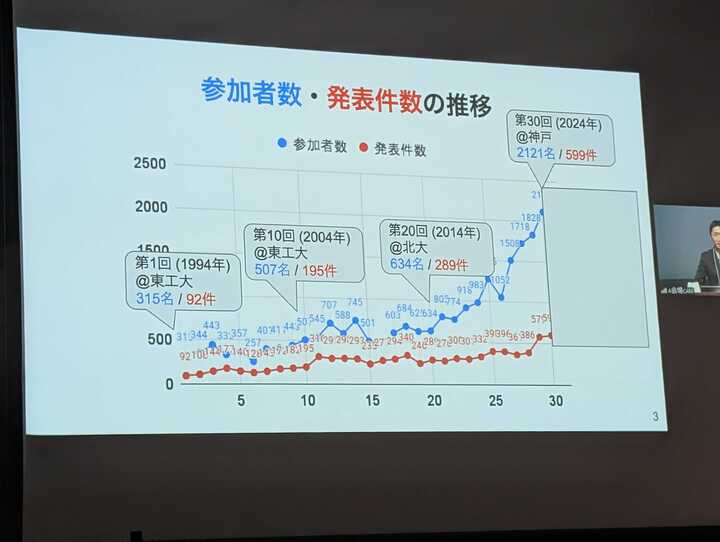

2023年あたりから LLM を用いた研究がすっかり主流となった一方で、LLM を使うだけでなく評価する研究も一定以上の盛り上がりを見せており、今年はどのような研究発表が聞けるのか、とても楽しみにして参加しました。
なお、コミューン株式会社はシルバースポンサーとして協賛させていただきました。このような素晴らしい会をサポートすることができ、とても嬉しく思います。
この記事では NLP2025 にてコミューン株式会社より発表した研究と、その他の興味深かった研究について紹介します。
発表した内容について
P6-13 コミュニティ特有のハッシュタグ空間を考慮したマルチラベル候補生成器を用いる二段階推薦
論文: https://www.anlp.jp/proceedings/annual_meeting/2025/pdf_dir/P6-13.pdf
弊社は、クライアントごとにコミュニティの提供・運営をサポートする事業を展開しています。各コミュニティでは、投稿や検索など、ユーザー同士の交流をサポートする様々な機能を提供しています。このような個別のコミュニティを提供することで、新たな技術課題も生まれています。
その一つが推薦問題です。具体的には、投稿時に付与できるハッシュタグの推薦を対象としています。投稿テキストの入力後に適切なハッシュタグを推薦できれば、ユーザー体験の向上につながると考えています。
ただし、コミューンのサービスでは、基本的にコミュニティ間でのコンテンツ共有はできません。例えば、あるコミュニティでハッシュタグ1,2,3が使用され、別のコミュニティでハッシュタグA,B,Cが使用されている場合、これらを一括して推薦モデルを学習するのではなく、各コミュニティに対応したハッシュタグのみを推薦する必要があります。
この課題に対してはいくつかの解決策が考えられます。最も単純な方法は、コミュニティごとに個別の推薦モデルを用意することです。しかし、コミュニティは日々増加していくため、この方法ではモデルとAPIの管理リソースが際限なく増大してしまいます。
そこで本研究では、単一の推薦システムでありながら、各コミュニティに対応したハッシュタグ推薦を実現するシステムの開発に取り組みました。
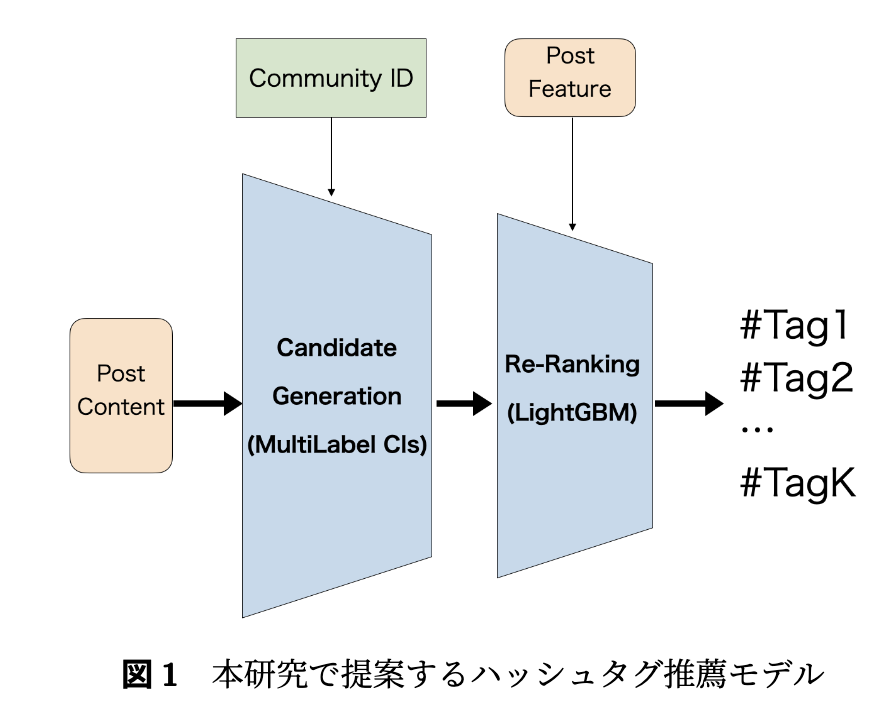
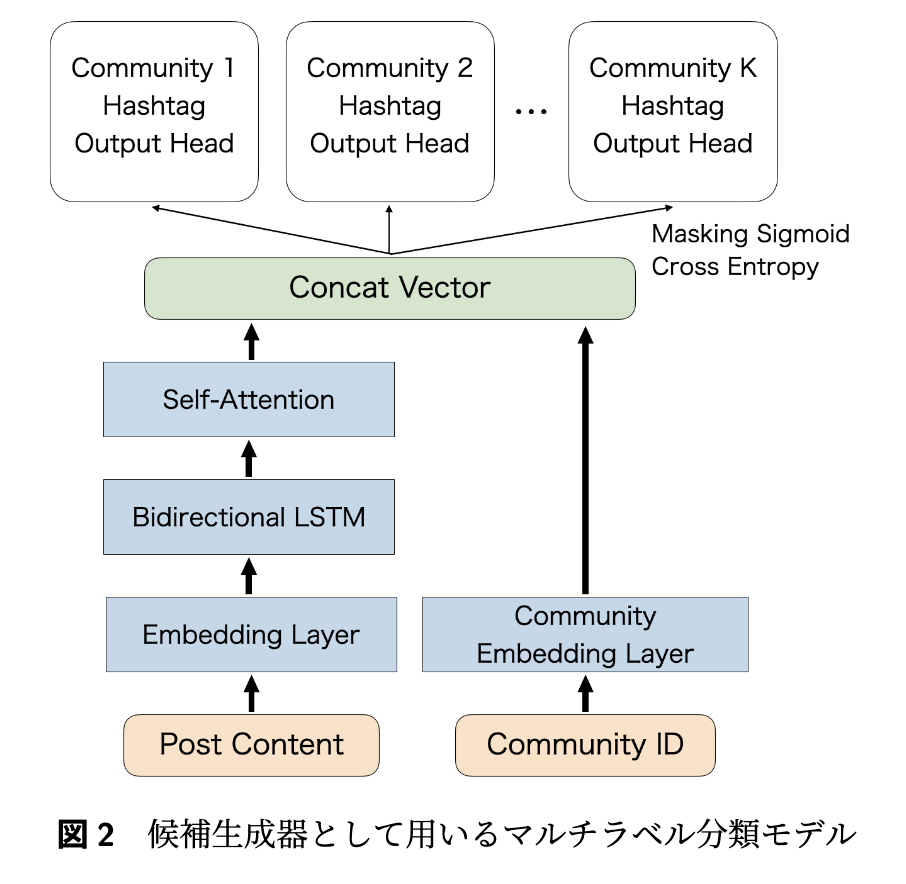
提案手法として、シンプルなTwo-Stage推薦をベースにしました。候補生成器にはマルチラベル分類器を採用し、各コミュニティに対応したハッシュタグ出力ヘッドを実装しました。入力は投稿コンテンツ文とコミュニティIDで、出力時には対象コミュニティ以外をマスクしてsigmoidで活性化し、BCEで損失計算を行います。これによりマルチタスク学習の効果を狙いました。この設計により、複雑な処理を必要とせず、コミュニティごとのフィルタリングとマルチラベル分類によるスコアリングの両方を効率的に実現できます。
この段階で得られた候補に対し、2nd-stageではLightGBMでスコアリングを行い、スコアの降順で並び替えたものを最終的な推薦結果として出力します。
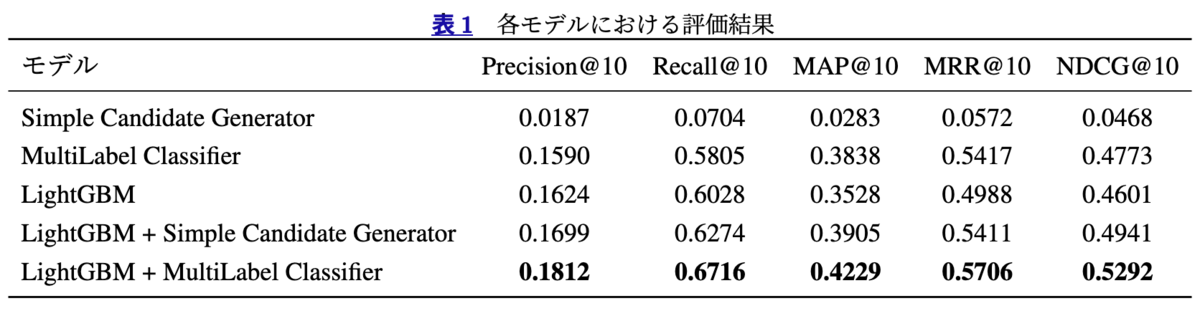
結果はこのようになっており、単独で各モデルを用いる場合よりもマルチラベル分類器と LightGBM を組み合わせる形が最も良い結果を得られました。また、投稿とハッシュタグの紐づきを学習したマルチラベル分類ではなく、文字列ベースでシンプルに候補を出力する Simple Candidate Generator との比較も行い、いずれもマルチラベル分類モデルを使うことでよりよい結果を得ることができました。論文中には表記できませんでしたが、GPT-4o との比較実験も行っており、(予想通りではありましたが)そちらよりも良い推薦精度を得られています。
こちらの論文で提案した推薦システムは既にコミューン上で提供できる状態が整っており、順次各コミュニティへの提供を行っていきます。実環境上で動作した際のオンライン指標についても分析していきたいです。
気になった・面白かった発表について
以下は NLP2025 で発表された研究の中から、深澤・樋口が特に興味深かったものをピックアップして紹介します。
チュートリアル1:言語モデルの内部機序:解析と解釈
紹介: 深澤
スライド:
https://speakerdeck.com/eumesy/analysis_and_interpretation_of_language_models
近年 Transformer・LLM がなぜうまく動作するのかといった解析を行う研究は非常に盛り上がっています。様々な観点からの解析が行われているがゆえに全体を追うのが難しく、なかなか整理するのが難しいトピックですが、こちらのチュートリアルセッションでは言語モデルを理解するための手法として、内部表現・計算過程の解析と解釈についてこれまでの研究をまとめていった後、その手法に限界があることを認めつつも前に進んでいる部分に触れて締めくくる、というものでした。
(感想) 個人的には注意パターンの分析にずっと興味があり、今回触れられた文頭・文末などの記号に注意が集まる現象について、ゴミ箱として機能している可能性がある、という研究を知れたのは自分にとって嬉しい収穫でした。
また、このようなタイトルのチュートリアルではありましたがその手法の限界にも触れられていました。言語モデルを表象計算機として捉えて分析を進めているが、「言語が世界の何かを表現していて、それを言語モデルは数学的な表現に落とし計算している」という暗黙的な仮定が本当に正しいのか、特定にニューロンを活性化させることでモデルの挙動を操作可能になったとして、その本質に迫れていると言えるのか、など。なのですが、それでもこの形で解析を進めていくことの意義も紹介され、改めてこの分野を追い続けて行く末をみたい、と感じました。
D1-4 ベイズ教師なし文境界認識
紹介: 深澤
論文: https://www.anlp.jp/proceedings/annual_meeting/2025/pdf_dir/D1-4.pdf
教師なし学習による日本語テキストの文境界認識の研究です。文字ごとの二値潜在変数としてモデル化し、セミマルコフモデルと動的計画法・MCMC 法を組み合わせて文字𝑛グラムベースの文分割を実現しています。X(Twitter) や BCCWJ での実験では、特に句点なしや絵文字などを含む非標準的なテキストにおいて、ルールベースや LLM を含む既存手法を上回る精度を達成しました。
(感想)特に自分が驚いたのは、BCCWJ に関する実験結果でした。BCCWJ から得られる文章を句読点や記号などを使わずつなげて、それを分割できるかというタスクが用意されており、LLM ならできるのかな?くらいの気持ちで見ていたのですが提案手法が圧倒的に良い結果となっていました。Slack でお話させていただいた際、タイ語などは句読点などがなく記述できるのでそれに似た問題となっていたとのご見解でした。今回は日本語コーパスでの結果でしたが、他言語でも概ね機能する枠組みなのだろうと理解しました。
個人的にこうした堅実な研究がとても好きなので、本会議初日からニコニコしていました。
A2-1 大規模言語モデルにおける複数の指示追従成功率を個々の指示追従成功率から推定する
紹介: 深澤
論文: https://www.anlp.jp/proceedings/annual_meeting/2025/pdf_dir/A2-1.pdf
本研究は、LLMの複数指示への同時追従能力を分析したものです。新規ベンチマーク「ManyIFEval」と「StyleMBPP」を用いて各種モデルを評価し、複数指示への追従成功率が個々の指示の成功率の積で推定できることを示しました。
また、指示数の増加に伴い成功率が大幅に低下することも確認され、この傾向は両ベンチマークで一貫していました。
(感想) 個々の指示に関する成功率をかけ合わせることで全体の成功率を推定できる、という結果を見たときは結構びっくりしました。指示の与える順番が異なったとしても同様の結果が得られるのでしょうか、という質問をさせていただいたのですが、今回は変わらなかったとのことです。コンテキスト長が短い設定での実験であるがゆえに lost in the middle 的な注意消失が起きなかった可能性が高いとのことだったので、でかいコンテキストでの実験結果も楽しみです!
A5-4 プロンプトに基づくテキスト埋め込みのタスクによる冗長性の違い
紹介: 深澤
論文: https://www.anlp.jp/proceedings/annual_meeting/2025/pdf_dir/A5-4.pdf
プロンプトベースのテキスト埋め込みモデルにおいて、次元数削減と異なるタスクでの冗長性を調査しました。分類・クラスタリング・検索タスクを調べたところ、分類タスクでは次元数を1%以下に削減しても性能維持が可能だったとのことでした。
固有次元と IsoScore を用いた分析により、分類・クラスタリングタスクの埋め込みは冗長性が高く偏った分布を示す一方、検索タスクは冗長性が低く広く分布することが分かりました。つまり、分類・クラスタリングは次元削減が可能ですが、検索タスクでは多くの情報量を保持する必要があるという結果が得られています。
(感想) 分類タスクで次元をシンプルに削減しても性能がほぼ維持される、というのが最大に面白いポイントですが、検索タスクと分類タスクとでそこまで大きな差が生まれるんだなあというのも個人的には気になりました。普段から割とランキング学習と分類学習とでそこまで埋め込みについて意識せずに取り組んでしまっていますが、この結果を踏まえると(プロンプト埋め込みでないとしても)タスク性質の違いからそれぞれ個別の調整が絶対必要だよな、と改めて感じました。
A8-1 似た単語の知識ニューロンは似た形成過程を経る
紹介: 深澤
論文: https://www.anlp.jp/proceedings/annual_meeting/2025/pdf_dir/A8-1.pdf
言語モデルの学習過程における「知識ニューロン」の形成を分析した研究です。Pythia-410M モデルにある単語が正解となる質問文を含むプロンプトを入力し,その続きをモデルに生成させるタスクを行わせます。その結果を知識帰属法を用いて分析し、「猫」「犬」といった意味的に類似した単語に対応するニューロンを調査しています。その結果、これらのニューロンは類似した形成過程を経て発達し、学習後も多くの共通ニューロンを持つことが分かったとのことでした。言語モデルが学習を通じて意味的なカテゴリ間の関連性を自然に捉えていることを示唆されている興味深い研究でした。
(感想) 国カテゴリだけが他カテゴリと異なり反応が弱かったのが気になりました。質問を踏まえた議論では「国だけが固有名詞で、動物カテゴリなどとは異なる性質だったから?」のような流れになっていました。大規模言語モデルがそれらをどのように捉えているのか、の差異に繋がるような重要な結果だったんじゃないかな、と個人的にも思います。
A8-6 従属節が分断された不可能言語を言語モデルは学習するのか
紹介: 深澤
論文: https://www.anlp.jp/proceedings/annual_meeting/2025/pdf_dir/A8-6.pdf
言語モデル(GPT-2)の学習能力が人間とどのように異なるのかを調べるため、「従属節が主節により分断された」という人間には不自然な「不可能言語」を作成し、その学習可能性を分析した研究です。
「従属節は他の節で分断されない」というのは自然言語に共通の性質であると知られており、本研究ではこの性質を意図的に崩した言語を作成して、言語モデルがそのような構造を学習できるかを検証しています。BabyLM データセットを元に可能言語と不可能言語を作成し、それぞれの言語を用いて GPT-2 を学習させた後、それぞれの生成確率について比較を行っています。
実験の結果、GPT-2 モデルは不可能言語を可能言語よりも学習しづらく、特に不可能言語では、主語と述語の対応関係の学習が困難だったことが示されていました。
(感想) 不可能言語、という先行研究がそもそも知らなかったのですが、とても面白い概念で勉強になりました。LLM など表現力の高いモデルはコーパスを丸覚えしているのでは、という話が従来からあったと思うのですが、今回の結果を踏まえると何らかの言語構造をどうやら認識しているらしいということがわかり、とても有益な結果だったと思います!面白かったです。
チュートリアル1:ことばの意味を計算するしくみ
紹介: 樋口
資料: https://speakerdeck.com/verypluming/kotobanoyi-wei-woji-suan-surusikumi
本チュートリアルセッションでは、ことば(自然言語)の意味が多岐にわたる側面と性質を持つため、自然言語処理、言語学、認知科学といった多様な研究分野が連携していると説明した上で、意味を捉えるための二つの主要なアプローチが提示しています。
一つは、自然言語処理の立場から、言葉が使われる文脈、すなわち周辺に現れる語に基づいて意味を理解しようとする(分布意味論、使用説)です。もう一つは、計算言語学の立場から、文全体の真理条件(どのような状況で文が真となるかという条件)に基づいて言葉の意味を捉えようとするアプローチ(形式意味論、真理条件説)です。
(感想) この発表を聞き、意味を捉える単位は単語、フレーズ、文など複数存在する上に、同音異義語、多義性、発話における省略など様々な曖昧性が含まれていることを知り、言葉の意味を理解することは決して容易でないことを改めて感じました。
また、自分が普段の業務や趣味で触れている自然言語処理は、言葉を理解するための重要な手法であるが、それとは異なる視点から言葉を解釈しようとする計算言語学という分野があること、そしてそれぞれの立場が持つ論理体系を改めて認識できました。
LLM は、大量のテキストデータから統計的に次に来る言葉を予測するという比較的シンプルな学習規則に基づいていますが、この過程で、別の立場である形式意味論が扱うような合成性や体系性といった知識をある程度獲得しているのではないかと思い、興味深いなと感じました。
P3-2 自動アノテーションを導入したG-Eval による英文要約課題評価
紹介: 樋口
論文: https://www.anlp.jp/proceedings/annual_meeting/2025/pdf_dir/P3-2.pdf
本発表では、LLM が英語要約の評価プロセスを自動生成するG-Evalという手法をさらに改善し、要約文の重要部分に自動生成したタグを付ける方法が提案されました。
提案手法では、LLM が評価ステップを作成する際に、要約文内の重要な概念や表現を特定するためのタグを自動的に生成し、付与しています。このタグを用いて要約文の該当箇所を囲むことで、より人内容に基づいた質の高い評価が可能になることが示唆されています。
(感想) LLM に評価方法を詳細に指示するアプローチは一般的ですが、評価対象のテキストに対してタグを用いて装飾するという手法は、新しい視点であると感じました。このタグ付けは、LLM が評価の際に特定の関心領域にアテンションを集中させるような効果を持っていそうです。また、LLM を活用することで、このタグを貼る場所をある程度ファジーに柔軟に設定できますし、自動生成されたタグを評価根拠として示すことで、評価プロセスの透明性が高まるので、手法の有用性を感じました。
Q2-4 llm-jp-judge: 日本語LLM-as-a-Judge評価ツール
紹介: 樋口
論文: https://www.anlp.jp/proceedings/annual_meeting/2025/pdf_dir/Q2-4.pdf
本研究では、LLM-as-a-Judge が広く用いられるようになってきた背景を踏まえ、日本語 LLM の LLM-as-a-Judge 評価を統一的に扱えるツール "llm-jp-judge" が提案されました。
提案された llm-jp-judge は、複数のLLMを用いて評価を行い、その評価結果が人間による評価とどの程度合致しているかをピアソン相関係数を用いて評価しています。また、評価項目も品質(正確性、流暢性、詳細性、関連性、総合評価)、マルチターン対話、安全性と多岐にわたり、LLM の能力を多角的に評価できる点が特徴です。最後にメタ評価のパートで、人間の評価と LLM による各評価項目において、どのような差があるのか考察がなされていました。
(感想) 正確性、流暢性などは、人間に比べてかなり甘い評価をすることが面白かったです。流暢さなど曖昧な概念に対して高いスコアをつけやすというのは実際に LLM を使った感覚とも合致しています。評価に用いられる品質評価用プロンプトは一度に複数の評価項目に対して、1から5のスコアを生成するシンプルなものであり、これで人間との評価の高い一致度を示したことに驚きました。
P7-7 chakoshi: カテゴリのカスタマイズが可能な日本語に強い LLM 向けガードレール
紹介: 樋口
サービスサイト: https://chakoshi.ntt.com/
論文: https://www.anlp.jp/proceedings/annual_meeting/2025/pdf_dir/P7-7.pdf
入出力に含まれる不適切な発言や、AI モデル自体が有害なコンテンツを生成するリスクに対応するために、日本語に特化した LLM 向けガードレールツールである「chakoshi」が紹介されました。
chakoshi は gemma-2-9b-it をベースとしたモデルで、大きな特徴として、防ぎたい話題を自然言語でカスタマイズできます。
(感想) プロダクトとして実用化を見据え、軽量なモデルでありながら、テキストベースの入出力に特化し、様々なチャットモデルと疎結合に動作するといったシステム要件が明確に定められている点は、実応用を考える上で非常に参考になりました。また、付録の判定結果に示されているように、日本語特有の曖昧な表現やステレオタイプに基づく発言など、複雑なニュアンスまで対応できる性能が非常に興味深かったです。chakoshi のように、ユーザー固有の要件に合わせてLLMの入出力を調整する付加パーツのような技術は今後も増えるのかなと想像しました。
Q2-13 架空語に対するLLM の知ったかぶりの自動評価
紹介: 樋口
論文: https://www.anlp.jp/proceedings/annual_meeting/2025/pdf_dir/Q2-13.pdf
本研究では、シンプルなルールに基づいて存在しない言葉を LLM に与えてその意味を尋ねることで、LLM がねつ造、曲解、など意味を「知ったかぶり」する傾向を評価したものです。
実験の結果、LLM に対して「簡単に意味を教えて」というような曖昧なプロンプトを与えた場合、存在しない架空語に対しても意味をねつ造してしまうが「学習データに存在しない場合はそのことを明確にして意味を知らないと答えてください」というように、知らない場合にそう答えるよう明確に指示するプロンプトを用いた場合、LLM は高い確率で未知であることを正しく認識し、回答することが示されました。
また、LLM の応答例からは、LLM が未知の言葉であっても、その構成要素から意味を推測しようとする様子が窺えました。これは、LLM が言語のパターンを深く学習していることの表れである一方、存在しない意味をあたかも存在するかのように解釈してしまう原因にもなっていそうです。
(感想) それほど単純ではないと思われるこのタスクにおいて、GPT-4o mini のようなモデルであっても、適切なプロンプトを与えることで、ほとんどの場合に正しく応答できたという結果は注目に値します。プロンプトエンジニアリングの重要性を示すと同時に、最新の LLM は一定の未知語認識能力を備えているのかなと感じました。
全体的な感想
樋口
言語処理学会への参加は2019年以来でしたが、この6年で研究内容が大きく変化・進展しており、時代の変化の速さを痛感しました。理論的な研究から LLM の実用化事例まで幅広いテーマが取り上げられており、大変刺激的でした。
また、コミュニティサクセスプラットフォームを提供している会社に身を置いている立場として、2000人以上の参加者がオンライン・オフラインを問わず円滑に交流できるコミュニティの設計自体にも非常に参考になりました。
今後プロダクト開発において NLP を活用する機会がありそうなので、学会で得た知見を生かしつつ、何らかの形でアカデミアにも貢献していきたいと思いました。
深澤
言語処理学会に参加するのはこれで4回目くらいですが、年々面白さがパワーアップしていると感じます。LLM が盛り上がっていることがもちろん大きな理由ですが、数年前から始まった Slack 運用によって質問や盛り上がりが可視化されていることも大きな要因だと思っています。
自分は言語処理学会の Slack をとても楽しんでいて、いつものインターネットみたいな気持ちで気軽に投稿・質問・(本当に取るに足らない)感想を投げさせていただいております。そうしたことをしていると、どこからかものすごく博識な方が議論の助けをくれて一気に理解が進むことがあり、すごい環境だな、と思います。
来年も気軽に大変有益な議論ができるように、自分自身の研究を洗練させて投稿し、参加を目指します。