
こんにちは,コミューンで一人目の機械学習(ML)エンジニアとして働いている柏木(@asteriam_fp)です. 入社して5ヶ月ほど経ちましたが,今回漸く最近の取り組みを紹介できそうです.ML エンジニアは僕一人なので,専らの相談相手は ChatGPT 君の今日この頃です笑
はじめに
コミューンでは,企業とユーザーが融け合うコミュニティサクセスプラットフォームである commmune を提供しています.今回のブログは先日のプレスリリースでも発表された投稿レコメンド機能を commmune に導入したので,その機能を裏側で支えている機械学習基盤に関する内容を紹介します.
エンドユーザーに対して提供される機械学習システムを導入するのは初めての試みになり,まさにゼロからの出発なので,これから徐々に大きく育てて行く予定です!
- はじめに
- コミュニティプラットフォームにおける機械学習の可能性
- 機械学習プロジェクトに取り組むにあたり
- マルチテナントで実現する機械学習の難しさ
- レコメンドシステムのアーキテクチャ
- 今後について
- おわりに
コミュニティプラットフォームにおける機械学習の可能性
「AI × Community」の文脈において,競合を含め世界的にもまだまだ AI を積極的に導入し活用している例は少なく,この領域でプロダクトに AI を取り入れ,それを推進していくことは競合優位性を含めて非常に意味があります.
AI(機械学習)を用いることで,コミュニティ管理者には効率的に,また効果的に自社コミュニティに属するユーザーとコミュニケーションを取る手段を提供することでコミュニティ運用の最適化を,エンドユーザーに対しては,コミュニティにおけるパーソナライズ化されたユーザー体験の最適化を実現できると考えています.
機械学習の適用範囲は,管理者とエンドユーザーの双方に対して考えられます.例えば,管理者に対しては,LLM を用いたコミュニティ運営の効率化やユーザーグループへの打ち手の提案など,エンドユーザーに対しては,パーソナライズされた推薦・検索など,他には Trust & Safety なコミュニティのための違反投稿監視なども考えられます.また,ユーザー同士の関係性を分析することでより効果的な施策を考えることもできるでしょう.これらをコミュニティに貯まったデータ,テキスト情報や画像データを上手く活用することで,実践していこうとしています.
これらを見てもわかるように「AI × Community」領域ではやれることが多い一方で,それらがまだプロダクトに載っている例は少ないため非常にチャレンジングで可能性に満ちています!
投稿レコメンド機能とは
今回リリースされた投稿レコメンド機能は,エンドユーザーへの機械学習活用の第一歩になります.エンドユーザーが閲覧している投稿ページに,その投稿内容に似たおすすめの投稿を表示させる機能となっています.
興味関心がある投稿に関連する投稿をおすすめすることで,コミュニティ内を回遊するきっかけを作り,それによってコミュニティ滞在時間の増加や,投稿内容に対するリアクションなどを通してコミュニティに対するエンゲージメントを高める狙いがあります.
今回は比較的シンプルなロジックでレコメンド機能を実装しているので,今後はモデルの改善にも力を入れる予定です.改善を通して成果が得られたらブログでも紹介しようと思います!
機械学習プロジェクトに取り組むにあたり
まず,今回の機械学習プロジェクトでどういったプロセスで取り組んだのかをを紹介していきます.
言わずもがなですが,機械学習システムは一度導入したらそれで終わりではなく,継続的なデータの収集・計測・監視を行い,それらを用いて改善プロセスを回すことでプロダクトに価値貢献していく必要があります.所謂 MLOps の取り組みは必須だと考えています.そこで,機械学習プロジェクトでは,MLOps Maturity Assessment を参考にし,これを意識した取り組みを行いました.
Google が定義している MLOps levels の話や Microsoft が定義している MLOps 成熟度の話なども非常に参考になるのですが,プロジェクトレベルでどういった観点や項目を意識して取り組むことで,自然と MLOps を取り入れていけるかは書かれていないので,実際どう動けば良いかが初期段階だとわかりづらく,ML エンジニア・MLOps エンジニアの経験に頼る部分が大きくなります.
記事にも書かれていますが,基本的には以下の1~4をまずは抑えることが大事で,その中の全ての項目を初期段階から満たす必要はないと思いますが,これらを実践できると MLOps を実行可能な状態に持っていけると考えています.各項目に対して,取り組んでいる内容を軽く紹介しておきます.
- Documentation
- Traceability & Reproducibility
- Code quality
- Monitoring & Support
1. Documentation
ドキュメンテーションでの取り組みは,Design Doc を使って関係者とコミュニケーションを取りました.項目のテンプレートを紹介すると以下のような感じで,関係者にヒアリングしたり,自分で考えたりして基本的には ML エンジニアである僕が全ての項目を埋めています.
- Overview - Context - Issue:何が課題か - Why:なぜその課題を解決する必要があるのか - Who:誰を対象としたものか - Values:得られる価値は何か - Scope - Background - Goals / Non-goals - Solution / Technical Architecture - System Context Diagrams - Alternative Solution - Milestones - Operations
PO / PdM とは,Context から Goals までを主に認識合わせをし,Solution / Technical Architecture などシステム周りの話はソフトウェアエンジニアと認識合わせをし,ディスカッションしながら詰めていきました.どういった機械学習モデルを使うか,どういった機械学習システムを構築するかもドキュメントに整理し,この Design Doc にリンクを貼ってそのプロジェクトのドキュメントハブとしても利用しています.
※ 現状は上記の項目ですが,残しておくべき・コミュニケーションを取るべき項目があればアップデートして行く予定です.
2. Traceability & Reproducibility
ここでのトレーサビリティや再現性の取り組みとしていくつか紹介すると,
- CDKTF を活用したインフラの IaC 化
- CD による各環境への自動適用
- 各環境で同一データの参照
- どの環境からでも本番へのデータアクセスが可能な状態
上の2つの取り組みは後ほど紹介するので,割愛します.
3つ目の「各環境で同一データの参照」ですが,システム開発する場合には一般的に,開発環境と本番環境の最低2つを用意して進めると思います(場合によってはステージング環境を用意することもあると思います).この時,機械学習を扱う点において問題となるのは,開発と本番環境で違うデータを使う・データ量が全然違うといった状況があります.これの何が問題かというと,本番を想定して開発をするわけですが,実際流れてくる本番のデータパターンを網羅できておらず,開発環境だとエラーにならないが,本番環境で動かすとエラーになってしまうという問題に出会う可能性があります.なので,可能であるならばどの環境からでも本番環境へのデータアクセスが可能な状態にし,それを使って開発ができる状態が望ましいです.この時,権限などをコントロールしながら,同一のデータを参照できるようにする必要があります.機械学習パイプラインの中で実行されるスクリプト内で無駄に if env == 'dev': などはしたくないですよね.
3. Code quality
ここでは,コードの質を保つためのテストやレビューの話になります.CI による自動テストは後ほど紹介します.レビューは ML エンジニアが一人しか居ない状況だと難しかったりするので,今後改善して行きたいと思っています.あとは ML モデルに関するテストも徐々に充実させて行きたいと思っていますが,現状は優先順位を決めながらなので,少し後回しになっています.
4. Monitoring & Support
モニタリングに関しては後ほど紹介するので,コストに関して触れておくと,例えばバッチレコメンドかつマルチテナントの場合,毎日各テナントに対してレコメンドリストを生成するので,1つ当たりは小さくても全体で見ると機械学習パイプラインに関するコストが結構かかってきます.なので,1ヶ月でどれぐらいかかっているかは把握するようにしていて,我々の場合は Vertex AI Pipelines を使っているので,簡易的に確認する時には,GCP の APIs & Services の Vertex AI API を見ています.
以上が簡単ではありますが,MLOps Maturity Assessment の取り組みの紹介になります.その他には重複する部分もありますが,ML Test Score に書かれている4項目も考えるべきトピックとして考慮しています.これらのガイドラインを手元に置きながら,プロジェクト・システム作りをすることで,継続的 / 持続可能な MLOps を進められると思っています.
これらを進める上でも関係者の理解と関係者間でのコミュニケーションを欠かさないというのは必須になってきます!
マルチテナントで実現する機械学習の難しさ
今回結構苦労した & 難しかったのは,マルチテナントの状況下でどのようにして機械学習システムを構築していけばいいかでした(今も正直悩んでいることは多くあります笑).僕自身マルチテナントでの機械学習システムをゼロから作り上げる経験はなかったので,何を意識すればいいか,またハマりポイントは何かなど予備知識がない状態からのスタートでした.
その中で特に考えるべきなのは,以下の3つかなと思います.
- 自動化
- スケーラビリティ
- 共通化
これらは別にマルチテナントだからというわけではないですが,特に身に染みて感じています.
例えば,モデル開発1つ取ってもマルチテナントでなければ,モデル学習用のパイプラインを1つ用意して,1つのモデルファイルを管理して…と進められますが,マルチテナントの場合はそれがテナント数必要になるケースもあります.なので,これらを動かす環境もですが,システムを組む上でスケールするかどうかはとても大切になってきます.
他には,パイプラインを定期実行するためのスケジューラーをテナント数用意して管理するのは正直無理です.そのため,できるだけ共通化できる部分は共通化したり,処理をループさせながら必要なものを生成するなど,中間ファイルなどはテナント数分管理する必要が出てきますが,Functions, Components などはできるだけ少なくする取り組みが必要になります.
その他だと,データの見方も難しく,モデルに関するメトリクスやビジネスメトリクスもコミュニティ毎に出てくるので,それをどう判断すればいいか,共通化しすぎるとどこかに対応できなかったりと,基準や判断の設定が悩ましい場面によく遭遇することが増えたと感じています.
レコメンドシステムのアーキテクチャ
コミューンでは,GCP を活用しているので,GCP の各種マネージドサービス上で機械学習基盤を構築しています.今回はバッチレコメンドの形で投稿レコメンド機能を提供しています.
機械学習基盤としては,以下を大事にして取り組みを進めています.
- 安定的に動き続けること
- エラーに気づける仕組み作りをすること
- 変更が容易であること
機械学習チームでは,これらを通して基盤の信頼性を高めてサービスを常に提供できる状態を目指しています.そのために機械学習関連の施策だけに時間を注ぐのではなく,基盤整備のための時間も確保するようにしています.
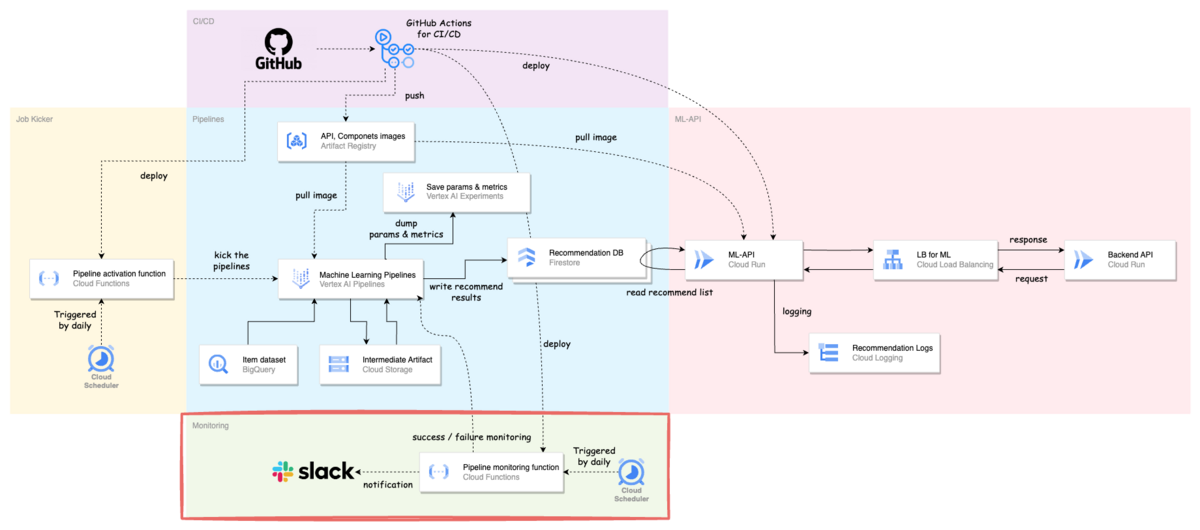
機械学習システムの全体像
システムのアーキテクチャは下図のようになります.
- 太線矢印が「データの流れ」
- 点線矢印が「制御の流れ」
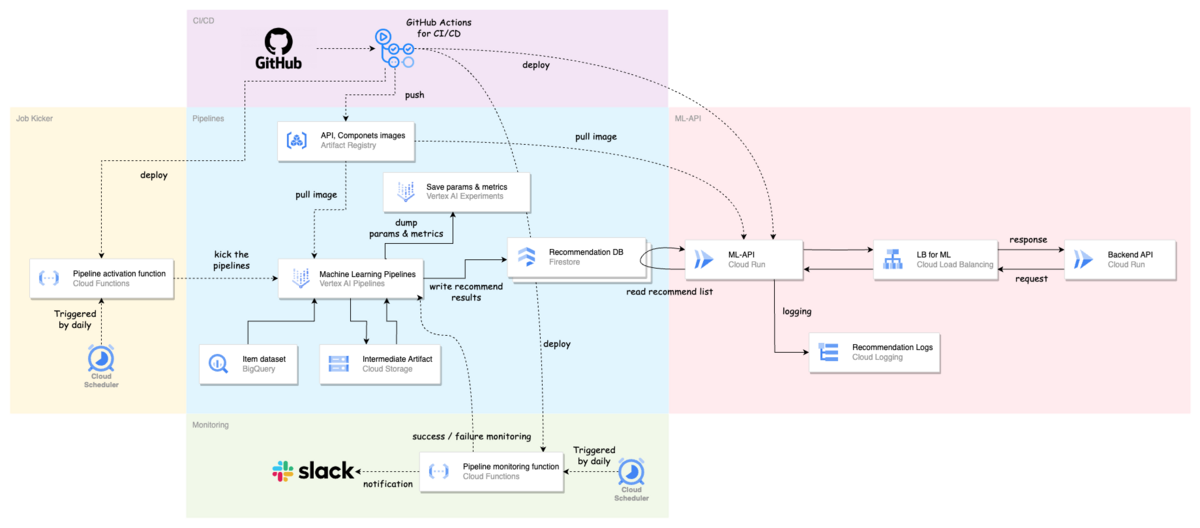
技術スタックは以下のような感じです.
- 機械学習パイプライン:Vertex AI Pipelines
- 実験管理:Vertex AI Experiments
- 機械学習用 API(ML-API):Cloud Run
- フレームワーク:FastAPI
- DWH:BigQuery
- データベース:Firestore(レコメンド結果保存用)
- ストレージ:Cloud Storage(アーティファクト保存用)
- モニタリング:Cloud Scheduler + Cloud Functions(パイプライン), Cloud Monitoring(API)
- CI / CD:GitHub Actions
- スケジューラー:Cloud Scheduler + Cloud Functions(パイプライン定期実行用)
- コンテナレジストリ:Artifact Registry
commmune の機械学習部分とバックエンド部分のインターフェースとして,ML-API を置く方法を採用しています.これは後述しますが,ML-API で柔軟にユーザーとアイテムの出し分けができるのと,本体に開発依頼を出すことなくある程度 ML 側で諸々を吸収できるようにしておくという意図があります.
もう少し細かめに各役割を紹介していきます.
継続的な学習のための機械学習パイプライン
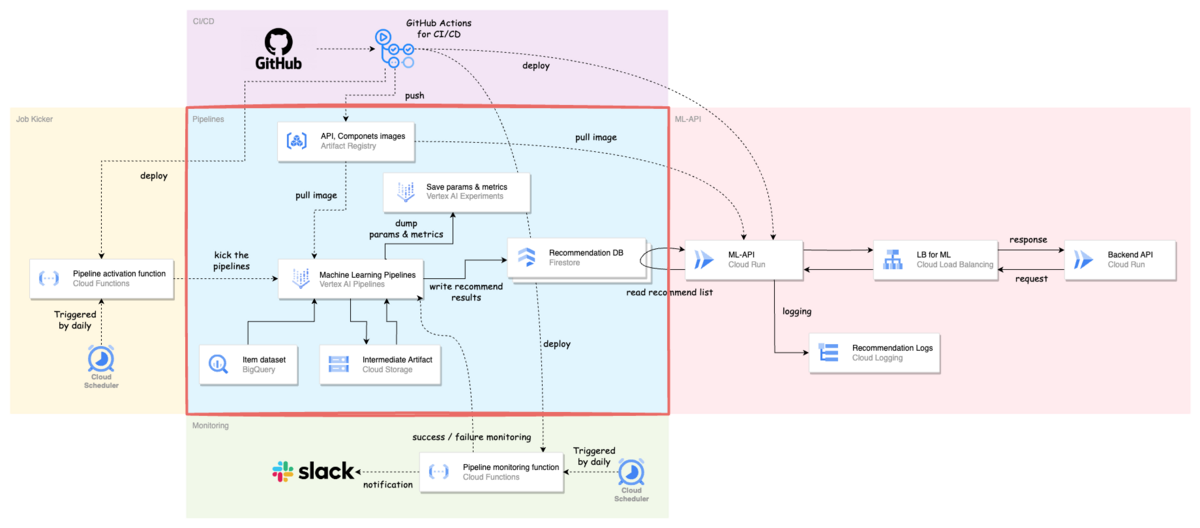
機械学習パイプラインは,バッチレコメンドにおけるレコメンドリストを日々生成する役割を担っています.機械学習パイプラインには GCP の Vertex AI Pipelines を採用しました.
選定理由として,以下が挙げられます.
- マネージドサービスである
- コンポーネント毎に独立して管理できる
- コンポーネント毎に適切なスペックのマシンを割り当てることができる
- これらコンポーネントを柔軟に組み合わせてパイプライン化ができる
マネージドサービスであることは,一人で開発していく上でとても大きいです.また,コンポーネントとしてモジュール化できると,別のパイプラインでも再利用できたり共通化できるのというのがあります.
パイプラインの流れはざっくりと以下の通りで,初回というのもあり,かなりシンプルな構成になっています(細かい部分も知りたい場合は是非カジュアル面談で聞いて下さい!).
- BigQuery から投稿データを抽出し,投稿ベクトルを計算する
- BERT 系の学習済みモデルを用いて Embedding を作成しています
- 各投稿に対して,関連度(類似度が高い)投稿をランキング化する
- 前ステップで計算された Embedding を用いて,annoy という ANN ライブラリを使用して,類似度の高い投稿を必要な分だけ取得するようにしています
- レコメンド結果を Recommendation DB へ書き込む
- ML-API でレコメンド結果を素早く取得できるように,KVS の Firestore にデータを保存しています
また,アーキテクチャ図にあるように,パイプライン内で使用したパラメータや中間生成物のメタデータは Vertex AI Experiments に保存するようになっています.テナント毎に日々のパイプラインの結果が集約されて確認できるのでとても良いです.
結果の保存先としては,API からの呼び出し + コスト面も考慮して Firestore を選択しています.最近 Firestore は1つの GCP プロジェクト内で multiple databases に対応するようになったので,マルチテナントで複数の ML サービスが動く環境だとありがたいアップデートもされています.
参考:Manage multiple Firestore databases in a project
多少ハマったポイント:
- Vertex AI Pipelines とライブラリ等との相性
- Python のバージョンとパイプラインで使用するライブラリの組み合わせによってはコンポーネントのカスタムコンテナが Vertex AI Pipelines 上で動かない状態に陥った
- なので,なんやかんやで Python 3.9.16 に落ち着きました
- Vertex AI Pipelines のカスタムコンポーネントを動かすサービスアカウント
- 手前味噌ですが,以前整理したものをブログに書いています(参考:Vertex AI Pipelines のサービスアカウントで少しつまずいたので整理した)
パイプラインの定期実行
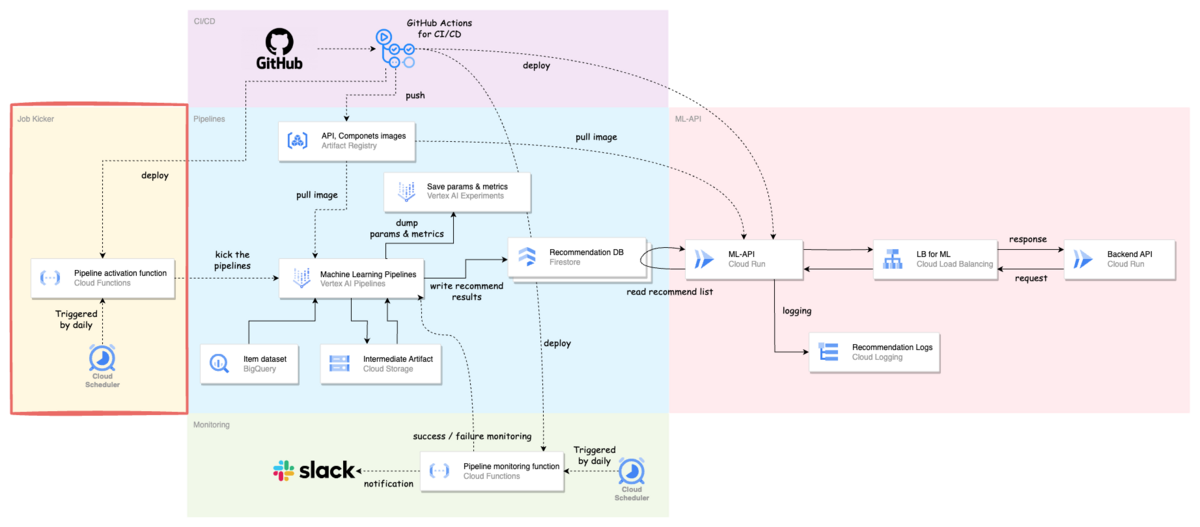
機械学習パイプラインを定期実行するために,Cloud Scheduler + Cloud Functions でスケジューラーを実装しました.Vertex AI でも最近 scheduler API が使えるようになり,パイプラインのスケジュール実行が可能になりましたが,引き続き自前で用意したものを使用する予定です.
理由としては,2つあります.
- マルチテナントの用途に対応するため
- 自前で用意したスケジューラーの中で,パイプラインを動かす対象となるテナントの自動追加と削除を行っているため
新しくサービスを提供する企業が増えた場合や残念ながら減った場合に,それらを1つ1つ手動で対応していては時間がいくらあっても足りません.また,抜け漏れや即時対応ができない可能性があるため,テナントの情報を管理しているテーブルからデータを取ってきて,その時点で動かす対象となるパイプラインをスケジューラーの中で都度計算し管理しているといのもあり,自前で用意したものを今は動かしています.
本体アプリケーションとのインターフェースとしての機械学習用 API(ML-API)
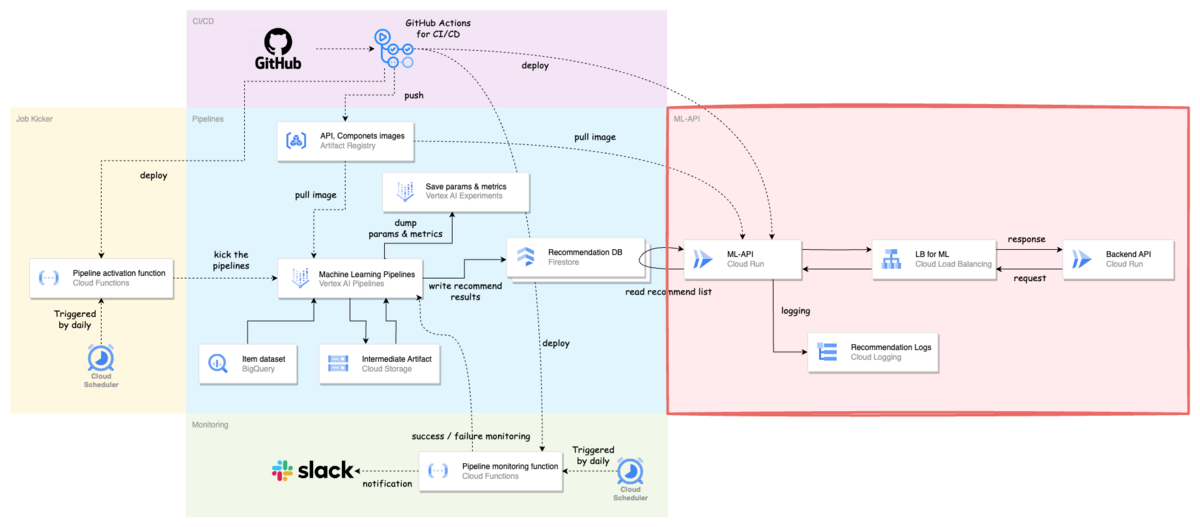
ML-API の役割は本体アプリケーションからのリクエストに対して,Recommendation DB からレコメンドリストを取ってきてそれをレスポンスとして本体に返すようになっています.
これだけだと,わざわざ API を用意しなくてもレコメンド結果を DB に保存し,それを本体に取ってきて貰うという方法もあるかと思います.
なので他の役割も紹介すると,
- AB テストのテナント・ユーザー振り分けを行う
- 必要なログ出力を ML-API からも行う
- 必要に応じてレコメンドリストのフィルタリングやハンドリングを行う
などになります.
例えば,分析のために使用するログの出力内容を変更したい場合に,開発チームに毎度毎度お願いするのはスピードも落ちますし,開発側も手が回らない場合もあります.そのため,ML 側だけで完結してできるということは,コントローラブルかつ改善サイクルを回しやすくすることにも繋がります.また,複数の Recommendation DB からレコメンドリストを取ってきて ML-API の中で再構築することも可能になります.
ただ,メンテナンス対象は増えるので,ML チームが一人だけの状態だと手離れはしにくくなってしまいます(自分がいつ居なくなっても回るようにすることも大事だと思います).
レコメンドログ
あるテナントのユーザーにレコメンドを提供した際に,どのテナントの・どのユーザーに・どんなロジックで・どんなレコメンドリストを提供したかを全て Cloud Logging に出力し,その結果を BigQuery に連携しています.
また,AB テストを実施した際に後で結果を集計するために必要な Control と Treatment の情報なども保存するようにしています.この辺りは「推薦システム実践入門 - 6.2 ログの設計」を参考にさせて貰いました!
今までの経験から,ユーザーがレコメンド結果をクリックし閲覧した時に表示されていたレコメンドリストが何であったか,それはどんなロジックで出されたものかを把握できないと,改善するにしても深い分析がしにくい状況でした.なので,ログ出力をしっかり行うことで,機械学習モデルの改善やユーザー行動の分析に少しでも手助けができると思い実装しています.
ログはより見やすいかつ分析しやすい状態にすべく,実際のクリック情報や本体アプリケーションのログ情報などとまとめたテーブルを作ろうとデータエンジニアと動き出している段階です.
機械学習パイプラインのモニタリング
モニタリングすべき項目は,以前 X (旧 Twitter) でポストしたものを見て頂けると色々とあって,これから取り組んでいきたいところなのですが,今回はパイプラインのモニタリングの紹介になります.
機械学習のモニタリングにおいてどの観点が必要なのか時々考えてるけど,この図はとてもしっくり来た.基本的には,Data・Model・Codeの3つを押さえておくというのはありつつ,もう少し深掘りした時に何が必要かが理解しやすい. pic.twitter.com/X6vPs2lWF4
— asteriam (@asteriam_fp) 2023年8月30日
現状,マルチテナントで100以上の機械学習パイプラインが1日に1回だけ動き,これらのエラー監視を定刻に行っています.エラーになった場合の通知は,Slack に連携するようにしています.
モニタリングの方法としては,Cloud Monitoring を使って簡単に監視することもできますが,Cloud Scheduler + Cloud Functions で監視を行うことにしました.
こちらを選択した理由としては,今のところ2つあります.
- 特定のスケジュールでジョブを実行したい
- エラーになったテナントに対して条件指定でアクションを設定したい
エラーになったテナントに対して,まとめてリトライ処理を行ったりできるようにしておきたいというのがあったり,モニタリングしたいパイプラインを制御できるようにしておきたいというのがありました.
一方で,このようにシステムを用意すると,例えば Cloud Scheduler が定刻に動いているか,エラーになっていないかに気づける仕組みが必要になったりで,監視のための監視みたいになっているのはよろしくないなとも感じています.
今後はパイプラインだけでなく,データのモニタリングなどモニタリングすべき項目や内容を整理し,モニタリング環境を整えていきたいです.
機械学習リソースの CI / CD
CI / CD には GitHub Actions を使用しています.機械学習パイプラインや API などデプロイが頻繁に行われる可能性が高いものに関しては,ビルド & デプロイは自動でできるようにしています.
CI (Continuous Integration)
テストに関しては機械学習の場合,何をどこまで行えば良いかは常に付きまとう課題です.本当は実施するべきなのはわかっているけど,なかなか手が回らなかったりもします.我々も御多分に漏れずまだまだ不十分な状態ですが,現状は以下を実施しています.
CI で実施している内容
- Linter & Formatter
- flake8, isort, black
- 単体テスト
- パイプラインのコンパイルチェック
- Vertex AI Pipelines では,使用するパイプラインをコンパイルする必要があり,そのコンパイルができるかのチェックを行っています
Linter & Formatter では,mypy による型チェックが現状ではできていないので,ここは早めにしたいと考えています.また,これらをまとめた pysen, ruff を使ってスッキリさせるのもありだと思っています.
CD (Continuous Delivery)
機械学習パイプライン,ML-API で必要になるものを GitHub Actions のワークフローで自動デプロイするようにしています.
- Docker Image のビルド & Artifact Registry へのイメージのプッシュ
- Cloud Functions, Cloud Run, Cloud Scheduler のデプロイ
もう少し改善したい or 検討したい点はいくつかあります.
- 環境毎に用意している YAML ファイル
- 環境毎に GitHub Actions の YAML ファイルを用意していてファイル数も増えて非効率なので,この辺はもう少しスッキリさせたいです
- 機械学習パイプラインの各コンポーネント毎に用意している Dockerfile
- 機械学習パイプラインで使用しているコンポーネントに対してそれぞれ Dockerfile を用意していますが,各ファイルで使用する同じライブラリのバージョン管理だったり,コンポーネントが増えると複雑になったりするので,Docker Image を1つにするなど改善できると良さそうです
Vertex AI Pipelines,Component毎の環境やライブラリ用意できるのは良い反面,Dockerfileやpoetryのファイルを準備して管理するのファイル数多くなったり,Component間の関係性を統一できなかったりするので何か良いやり方ないかな?
— asteriam (@asteriam_fp) 2023年7月2日
- 機械学習パイプラインコンポーネントのビルド環境
- イメージのビルドに時間がかかるものもあるので,それらを Cloud Build で実行できるようにする
その他
機械学習システムで利用している GCP のインフラリソースに関して,それらの一部を Cloud Development Kit for Terraform (CDKTF) で IaC 化しています.
SRE チームのメンバーに協力して貰いながら,以下のリソースを管理しています.
- Service Account の IAM ロール
- Secrets Manager
- Cloud Storage のバケット
- Artifact Registry のリポジトリ
- Cloud Load Balancing
TypeScript なので個人的に慣れない部分もありますが,手動で作成・管理するよりは圧倒的に開発者体験が良いので,助かっています!
今後について
プロダクトにおける機械学習の活用は始まったばかりなので,これから組織・プロダクト共にスケールアップさせて行く予定です.
- チームに関して
今は ML チームに関しては僕一人で機械学習全般を見ていますが,データサイエンティストが一人決まっており,もう一人採用を進めている状態です.データサイエンティストが仮説検証を進めて行く中で,プロダクトに導入したい機械学習サービスは今後どんどん増えていくと思うので,それを担っていく ML/MLOps エンジニアの採用も今後は進めて行く予定です.
チームも立ち上げの段階で,機械学習基盤の構築・運用・改善もまだまだこれからなので,新しい取り組みも含めてやること/やれることはいっぱいあって楽しいと思います!
- プロダクトにおける機械学習活用に関して
今回のレコメンド機能のモデル改善もありますが,マルチテナントにおけるモデル開発はチャレンジングな課題だと思います(共通モデルか個別モデルかなど).
機械学習の活用に関しては先にも触れましたが,行動ログを用いたパーソナライズレコメンデーションとそのニアリアルタイム化への取り組み,新着投稿に対するコールドスタート問題の解消などを考えていたり,顧客要望での機能開発などもあります.
おわりに
今回のブログはかなり長くなってしまいましたが,最後まで見て頂いてありがとうございます!まだまだ AI × Community の取り組みは始まったばかりなので,これからプロダクトの進化に合わせて機械学習基盤もどんどん進化させて行きたいです.
最後に,コミューンではプロダクトを成長させたいデータサイエンティストを募集しています!!もっと話を聞いてみたい方や,少しでも興味を持たれた方は,ぜひ一度カジュアルにお話させてもらえると嬉しいです.
僕宛に X (旧 Twitter) の DM 経由でご連絡頂いても大丈夫です!
https://commmune.notion.site/07f0b03f114e4ccfb4af849d7887dcb7commmune.notion.site