
こんにちは,コミューンで一人機械学習(ML)チームで機械学習エンジニアとして働いている柏木(@asteriam_fp)です.
今年ももうあと少しですね,やり残したことは今年のうちにしたいものですが,僕は最近やっとジムに入会して適度に運動を始めることにしました!運動はメンタルヘルスにも影響があり,心が落ち着いたり,前向きな気持ちになる効果があるそうで,まだそこまでの実感はないですが継続していきたいと思います!
はじめに
本ブログでは,前回のテックブログで紹介した投稿レコメンド機能の初回リリース時の課題であった新着投稿に対しても,ニアリアルタイムでレコメンドを提供できるようにした取り組みの紹介になります.
ただし,今回の取り組みは現状ではベストだと思いますが,理想的な状況ではないので,その辺りも最後に紹介したいと思います.
投稿レコメンド機能における課題
投稿レコメンド機能とは
弊社プロダクトである commmune 内での投稿において,投稿をクリックしその詳細ページが表示されると最下部に「おすすめの投稿」として,今見ている投稿と関連した投稿が表示される機能になります.
この機能は,
- ユーザーのコミュニティ内での回遊率向上
- 回遊を通して滞在時間の向上
- 目に留まった投稿に対して,スタンプやコメントなどのリアクションを通してエンゲージメント向上
を目指したものになっています.
リリース後の CTR を見ると数%となっており,ルールベースと比較すると2倍以上良い結果は出ていて,一定 ML によるレコメンド機能としての価値を出せていると感じています.
ここで,ルールベースの出力についても簡単に説明しておくと,ML によるレコメンドリストが生成されていない投稿に対しては,ロジックベース(直近のリアクションが多い投稿)のレコメンドを表示するようになっています.
課題
このレコメンド機能はいわゆるバッチレコメンド機能になります.1日に1回だけ ML パイプラインが起動し,それまでに投稿された全ての投稿に対して関連投稿を計算し,レコメンドリストを生成しています.
これに対していくつか課題がありました.
- ML パイプラインによってレコメンドリストが生成された後に投稿されたものに関しては,ML によるレコメンドができない
- commmune の現状のプロダクト特性上,新着投稿がユーザーに一番見られやすい構造になっているため,インプレッションやクリックされやすいのは新着投稿となっている.そのため,新着投稿に対して投稿詳細レコメンドができないと,機会損失になっている
- ルールベースでの結果は表示されるが,ML の方が CTR が高い
プロダクトサイドやお客様からも新着投稿に対しても ML によるレコメンドをできるようにして欲しいといった要望もあり,ML チームとしてもユーザーによる投稿がされた後,比較的早いタイミングで(バッチのパイプラインが動くまで待つ必要がなく) ML によるレコメンドをしたいと考えていました.
今回の課題はバッチレコメンドでの課題としてはあるあるだと思います.次の章では,現時点で我々がどのような方法で解決しようしたかを紹介します.
課題に対する解決策の検討
今回の課題は,ML によるニアリアルタイム1レコメンドが出来れば解決できると考えました.
選択した方法としては,Message Queuing Service (MQS) を利用した非同期処理による方法になります.
Message Queuing Service (MQS) を利用した非同期処理による方法
この方法として2パターン考えました.
- アプリケーションのバックエンドからイベントトリガーで Pub/Sub のような MQS にメッセージを流してもらい,それをML システムが受け取り非同期でレコメンド処理を行う方法
- ML-API にアクセスが来たタイミングでバッチで生成していた結果を Recommendation DB に確認し,無い場合には,ML-API がそれを判断し裏側で非同期にレコメンド処理を行う方法
どちらも非同期処理を行うという点では同じですが,トリガーとなるタイミングに違いがあります.また,これらの方法は,今回課題としていたユーザーへのレコメンドとして問題ない範囲でのニアリアルタイム性がある方法だと判断しました.
1つ目の方法について考えてみると,こちらは比較的オーソドックスなパターンではないでしょうか.Pros/Cons を整理してみると以下が考えられます.
- Pros
- 社内外含めて知見が色々とある
- スケーラビリティに優れている
- イベントトリガーに無駄がない
- Cons
- 使いたいデータがある度に毎回 Dev チームに送ってもらう必要があり,Dev チームに負担がかかる
- スキーマが確定していれば良いが,精度改善のためにあれもこれもとなる可能性がある
- 非同期処理を行うための推論サーバーやデータパイプラインに関するコストがかかる
- 使いたいデータがある度に毎回 Dev チームに送ってもらう必要があり,Dev チームに負担がかかる
こちらの方法は,ユーザーによる投稿がなされたタイミングで ML による推論を動かすことができるので,より無駄なくニアリアルタイムでレコメンドすることが可能です.一方で Dev チームで柔軟に対応できる開発体制がまだ十分整っていないという課題もありました.
2つ目の方法についてですが,こちらはややアドホックな形になります.こちらも Pros/Cons を整理してみると以下が考えられます.
- Pros
- ML チームだけで完結する仕組み
- スケーラビリティに優れている
- Cons
- 1度目の投稿閲覧がトリガーとなるため,1度目はルールベースが必ず表示される
- 推論サーバーやデータパイプラインに関するコストがかかる
こちらの方法は,ML チームだけで完結する仕組みになっているのが大きいです.非同期処理が走るタイミングが投稿時ではないという点がありますが,データ基盤が整備された暁には移行することも考えて ML チームだけで柔軟に対応できる方が現時点では望ましいと考え,最終的にこちらの2番目の方法で実装することになりました.
他には単純な方法として,パイプラインの実行頻度を上げる方法を考えましたが,こちらは以下の理由で却下としました.
- コミュニティ毎に実行頻度を決めるのが難しい
- 新着投稿がない場合は,無駄打ちをすることになる
- コストが非常にかかる
- スケーラビリティに劣る
- 既存のパイプラインを使い回す場合,パイプラインの起動や処理時間がかかる
この方法は既存の仕組みが使えるものの,あまり筋の良い方法ではないです.commmune はマルチテナントのシステムであるため,この方法ではコミュニティが増える毎にコストがどんどん増えて行きます.また,定期実行の場合,新着投稿が仮になかったとしても動くことになりますし,パイプラインの処理時間はコミュニティ毎に異なるため,それ毎に決めるのは容易では無いですし,リアルタイム性もほとんどなくなってしまいます.
また,他にも CDC (Change Data Capture) によるデータ同期を利用した方法なども考えましたが,現状一人しかいない ML チームだと,データ基盤までお守りをするのは難しいと判断し,こちらも導入を見送りました.ただしこちらは別用途でデータチームが求めていることもあり,将来的に ML で使用するデータもこちらに載せて ML チームもハンドリングできるようにすることがあるかも知れません.
投稿関連度の計算を非同期処理化
今回実装したシステムのアーキテクチャは以下になります.
※ 黄色の部分が新しく実装したものになります.
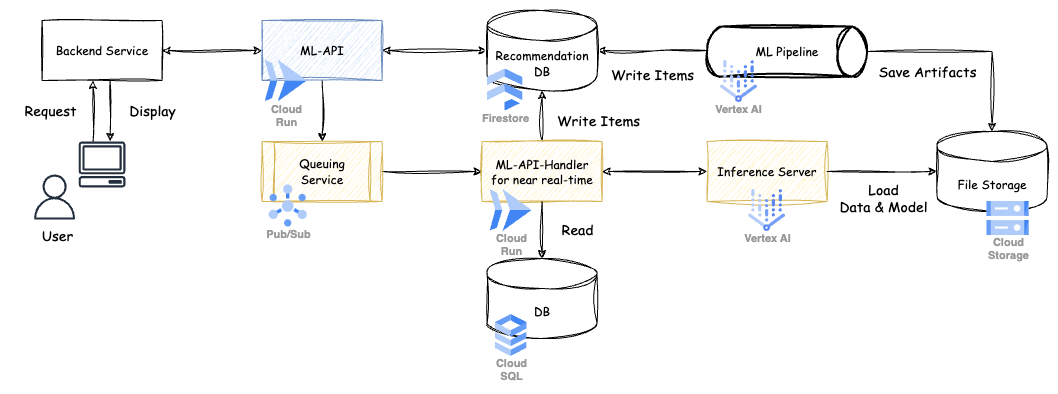
それぞれの役割を紹介して行きます.
- ML-API (Cloud Run)
- 本体アプリケーションからのリクエストに対して,レコメンド結果を返す役割
- 本体アプリケーションからリクエストを受けたら,ML-API はまず Recommendation DB にレコメンド結果を見に行く.ここでデータが無い,所謂新着投稿に対してはこの時点で Queuing Service にテナント情報と投稿に関する情報を送る
- 本体アプリケーションからのリクエストに対して,レコメンド結果を返す役割
- Queuing Service (Pub/Sub)
- 処理を非同期化するための役割
- ML-API から受け取ったデータをメッセージとして非同期処理用の ML-API-Handler for near real-time に送る
- 処理を非同期化するための役割
- ML-API-Handler for near real-time (Cloud Run)
- データの取得,推論結果の取得,レコメンド結果の保存などを行う役割
- データの取得
- 実際のデータを BigQuery の Federated Query を使って Cloud SQL に読み取りに行く
- 推論結果の取得
- 取得したデータを Vertex AI Endpoint で立てた Inference Server に渡し,推論処理を行い,生成されたレコメンドリストを受け取る
- レコメンド結果の保存
- Inference Server から受け取った結果を Recommendation DB に保存する
- データの取得
- データの取得,推論結果の取得,レコメンド結果の保存などを行う役割
- Inference Server (Vertex AI Endpoint)
- 投稿のベクトル化,投稿関連度の計算を行いランキング化する役割
- ML モデルによる Embedding や類似度の計算を行う
- 投稿のベクトル化,投稿関連度の計算を行いランキング化する役割
Inference Server についてもう少し補足しておくと,ML-API-Handler for near real-time に処理を全て押し込める方法もありましたが,ML に関連する処理を行う部分は Vertex AI Endpoint で処理を行うように役割を分離しました.これには2つ理由があります.
- ML 部分を独立して立てることで,推論処理が変わっても変更が容易なのと,ML モデルの AB テストも可能にするため
- ML インスタンスや GPU などのリソースを効率的に利用することも検討しているため
また,投稿関連度の計算は,Feature Store や Vertex AI Matching Engine などは使わず,事前に計算しておいた投稿に関する Embedding の情報が入ったファイルをリクエスト時に含まれるテナント情報を元に毎回 GCS からロードしています.
Feature Store や Vertex AI Matching Engine などを使うととても便利である反面,これらを GCP のマネージドサービスを使って構築すると非常に高価であるのと,現状のサービスの規模感やコストなどを考慮すると適切で無いため,今回は採用しませんでした.また,今回の機能において,Feature Store を導入しユーザーへのレコメンド提供の速度が上がることで,どれほどのビジネスインパクトを生み出せるかを考えてもそれほど大きくは無いというのも理由の1つです.
改善の結果
今回の改善の結果として,まだリリースして日が浅いですが,以下の結果に繋がっています.
- 1分以内に新着投稿に対しても ML によるレコメンドを提供できるようになった
- ユーザーへの価値提供としても,ルールベースより良いレコメンド結果を素早く出せるようになった
- ルールベースでの表示回数が減り,ML によるレコメンドの表示回数が増えたことで(具体的な数値は載せることができませんが)全体のCTR が上がった
- ルールベースでの表示が,ML による表示に変わったことで機会損失を減らせている
課題
投稿レコメンドのニアリアルタイム化によって価値を出すことができていますが,まだまだ課題もあります.
- ユーザーが一度投稿を見てからでないと非同期処理が走らない
- ユーザーが投稿を閲覧し,その投稿に対してレコメンド結果がない場合に非同期処理が走るため,少なくとも一度はルールベースを見せる必要がある
- 新着投稿に対する Embedding 結果を保存していないので,新着投稿同士の関連度が高くてもレコメンドすることができない
- Embedding のファイル更新は現状していないので,反映されるためには1日1回のバッチパイプラインが動くまで待つ必要がある
- 2つ目の課題にも関係しますが,過去の投稿に対してもバッチパイプラインが動くまで新着の投稿が反映されない(再計算はしていない)
共通化や汎用性を考えると,ユーザーアクションに関するログなどのデータ基盤を整える方法が筋が良さそうなため,来年はその辺りを整備した上でより良い仕組みに変えていきたいと考えています.
おわりに
真にリアルタイムにレコメンドを返すのは正直厳しいので,改善点はあるものの今回の取り組みは比較的リーズナブルな方法ではないでしょうか.まずはレコメンドを中心に色々とプロジェクトが動いているので,レコメンドに関する ML や MLOps に興味がある方は是非一度お話させて下さい!
最後に,コミューンでは機械学習エンジニアを絶賛募集しています!!もっと話を聞いてみたい方や,少しでも興味を持たれた方は,ぜひ一度カジュアルにお話させてもらえると嬉しいです.
僕宛に X (旧 Twitter) の DM 経由でご連絡頂いても大丈夫です!
https://commmune.notion.site/07f0b03f114e4ccfb4af849d7887dcb7commmune.notion.site
- ニアリアルタイムの定義は色々とあるかと思いますが,ここでは数分以内を指しています↩